
Multimodal AI
Multimodal AI refers to AI systems that can understand, interpret, and generate multiple data types, such as text, images, sound, and more.
What is Multimodality?
Modality refers to how something happens or is experienced, and a research problem is characterized as multimodal when it includes multiple such modalities.
Multimodality refers to the capability of a generative AI model to produce outputs across various types of data, commonly known as modalities, such as text, images, or audio. This feature is becoming increasingly vital as AI models find applications in diverse areas, from virtual assistants and chatbots to content creation and artistic expression.
Multimodal AI refers to artificial intelligence systems that can understand, interpret, and generate multiple data types, such as text, images, sound, and more. By synthesizing information across various modalities, these systems aim to offer more robust and versatile solutions compared to unimodal systems that focus on a single type of data.
Generative AI models form the backbone of multimodal AI. These models are trained on diverse datasets and learn statistical patterns from them to generate new, similar data. In the case of multimodal AI, these generative models are equipped to handle various data types.

Why is Multimodality Important?
Multimodality in AI is an essential advancement because it opens doors to a wide array of applications and brings more context-aware intelligence to machines. By integrating different types of data—text, images, audio, and more—models offer a versatile and comprehensive approach to problem-solving, far exceeding the capabilities of unimodal AI models that rely on a single data type. Processing and synthesizing different kinds of data enables a richer understanding of complex real-world scenarios. Multimodal AI can provide more accurate and contextually relevant outputs by merging various data sources.
.png)
Use Cases of Multimodal AI Systems
Computer Vision
Multimodal AI enhances object and context recognition, enabling a more comprehensive understanding of visual scenes. These systems contribute to enhanced contextual understanding and identification of objects.
Industry Applications
From overseeing manufacturing processes to patient diagnosis in healthcare, multimodal AI is reshaping various industries.
Language Processing
Multimodal models are advancing natural language processing (NLP) tasks like sentiment analysis by combining audio and text inputs.
Robotics
For robots to interact effectively with their environments, multimodal AI integrates data from sensors, cameras, and microphones to create a holistic understanding of the surroundings.
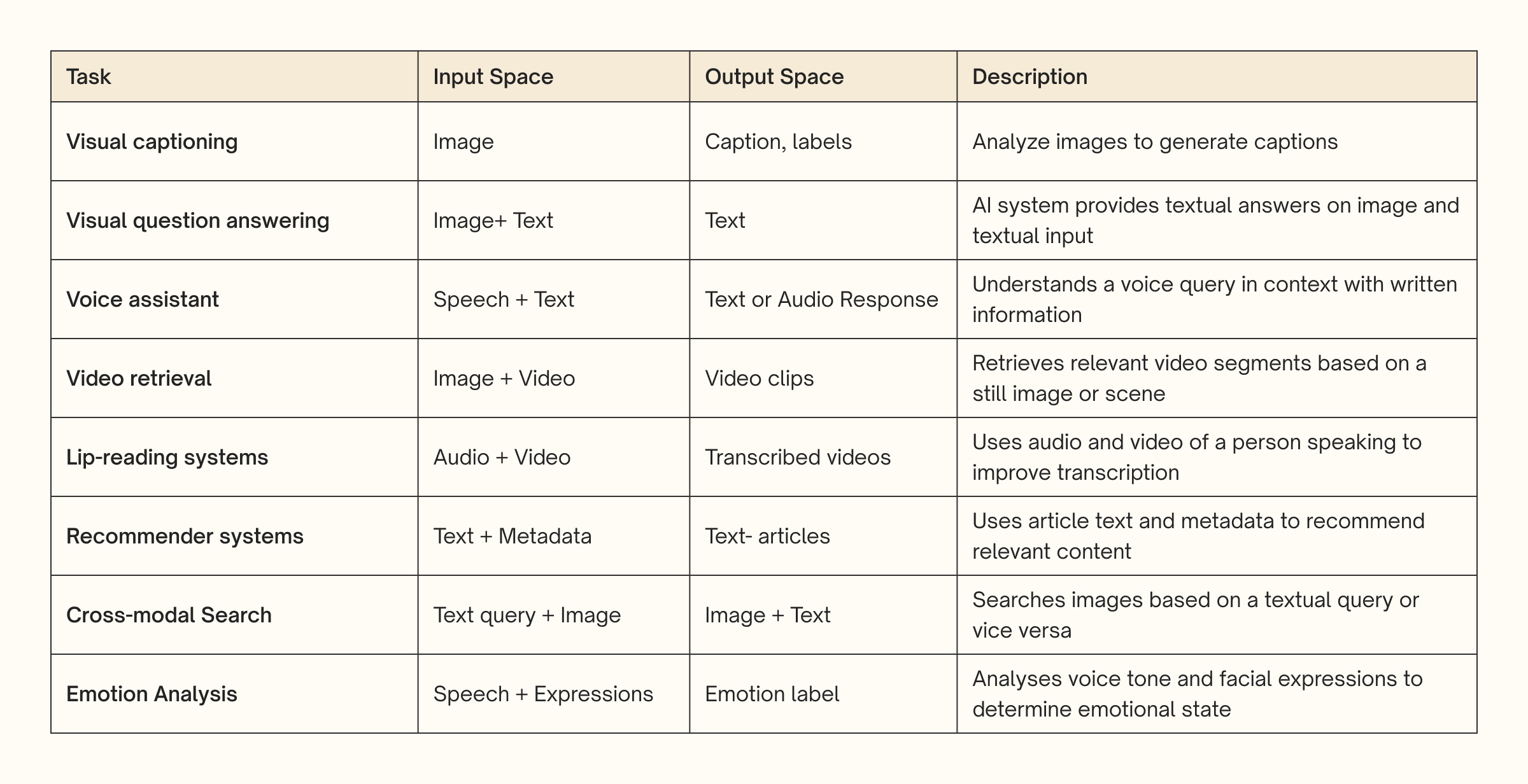
A Table Summarising Multimodal Applications
Further Reading
Multimodal Machine Learning: A Survey and Taxonomy